Before a commit is finished if any new stylesheet resources are going to
mount and we are capable of delaying the commit we will do the following
1. Wait for all preloads for newly created stylesheet resources to load
2. Once all preloads are finished we insert the stylesheet instances for
these resources and wait for them all to load
3. Once all stylesheets have loaded we complete the commit
In this PR I also removed the synchronous loadingstate tracking in the
fizz runtime. It was not necessary to support the implementation on not
used by the fizz runtime itself. It makes the inline script slightly
smaller
In this PR I also integrated ReactDOMFloatClient with
ReactDOMHostConfig. It leads to better code factoring, something I
already did on the server a while back. To make the diff a little easier
to follow i make these changes in a single commit so you can look at the
change after that commit if helpful
There is a 500ms timeout which will finish the commit even if all
suspended host instances have not finished loading yet
At the moment error and load events are treated the same and we're
really tracking whether the host instance is finished attempting to
load.
Follow-up to https://github.com/facebook/react/pull/26442.
It looks like we missed a few cases where we default import a CommonJS
module, which leads to Rollup adding `.default` access, e.g.
`require('webpack/lib/Template').default` in the output.
To fix, add the remaining cases to the list of exceptions. Verified by
going through all `externals` in the bundle list, and manually checking
the webpack plugin.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR:
- Updates Rollup from 2.x to latest 3.x, and updates associated plugins
- Updates deprecated / altered config settings in the Rollup plugin
pipeline
- Fixes some file extension and import issues related to use of ESM in
`react-dom-webpack-server`
- Removes a now-obsolete `strip-unused-imports` Rollup plugin
- <s>Fixes an _existing_ bug with the Rollup 2.x plugin pipeline on
`main` that was causing parts of `DOMProperty.js` to get left out of the
`react-dom-webpack-server` JS bundles, by adding a new plugin to tell
Rollup to treat that file as if it as side effects</s>
This PR should be functionally identical to the other existing "Rollup 3
upgrade" PR at #26078 . I'm filing this as a near-duplicate because I'm
ready to push this change through ASAP so that I can follow it up with a
PR that adds sourcemap support, that PR's artifact diffing seems like
it's possibly stuck and I want to compare the build results, and I've
got this set up against latest `main`.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This gets React's build setup updated to the latest Rollup version,
which is generally a good practice, but also ensures that any further
Rollup config tweaks can be done using the current Rollup docs as a
reference.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
- Made builds from the latest `main`
- Updated Rollup package versions and cross-compared the changes I
needed to make locally to get successful builds vs #26078
- Diffed the output folders between `main` and this PR, and confirmed
that the bundle contents are identical (with the exception of version
strings and the `react-dom-webpack-server` bundle fix re-adding missing
`DOMProperty.js` content)
## Summary
Now that React Native owns the definition for public instances in Fabric
and ReactNativePrivateInterface provides the methods to create instances
and access private fields (see
https://github.com/facebook/react-native/pull/36570), we can remove the
definitions from React.
After this PR, React Native public instances will be opaque types for
React and it will only handle their creation but not their definition.
This will make RN similar to DOM in how public instances are handled.
This is a new version of #26418 which was closed without merging.
## How did you test this change?
* Existing tests.
* Manually synced the changes in this PR to React Native and tested it
end to end in Meta's infra.
When rendering a suspensey resource that we haven't seen before, it may
have loaded in the background while we were rendering. We should yield
to the main thread to see if the load event fires in an immediate task.
For example, if the resource for a link element has already loaded, its
load event will fire in a task right after React yields to the main
thread. Because the continuation task is not scheduled until right
before React yields, the load event will ping React before it resumes.
If this happens, we can resume rendering without showing a fallback.
I don't think this matters much for images, because the `completed`
property tells us whether the image has loaded, and during a non-urgent
render, we never block the main thread for more than 5ms at a time (for
now — we might increase this in the future). It matters more for
stylesheets because the only way to check if it has loaded is by
listening for the load event.
This is essentially the same trick that `use` does for userspace
promises, but a bit simpler because we don't need to replay the host
component's begin phase; the work-in-progress fiber already completed,
so we can just continue onto the next sibling without any additional
work.
As part of this change, I split the `shouldSuspendCommit` host config
method into separate `maySuspendCommit` and `preloadInstance` methods.
Previously `shouldSuspendCommit` was used for both.
This raised a question of whether we should preload resources during a
synchronous render. My initial instinct was that we shouldn't, because
we're going to synchronously block the main thread until the resource is
inserted into the DOM, anyway. But I wonder if the browser is able to
initiate the preload even while the main thread is blocked. It's
probably a micro-optimization either way because most resources will be
loaded during transitions, not urgent renders.
CircleCI now enforces passing a token when fetching artifacts. I'm also
deleting the old request-promise-json dependency because AFAIK we were
only using it to fetch json from circleci about the list of available
artifacts – which we can just do using node-fetch. Plus, the underlying
request package it uses has been deprecated since 2019.
This doesn't need its own set of flags. We use things like `__PROFILE__`
in the regular feature flags file to fork for the `react-dom/profiling`
build so we can do the same here if needed but I don't think we actually
need to fork this anywhere as far as I can tell.
## Summary
The current definition of `Instance` in Fabric has 2 fields:
- `node`: reference to the native node in the shadow tree.
- `canonical`: public instance provided to users via refs + some
internal fields needed by Fabric.
We're currently using `canonical` not only as the public instance, but
also to store internal properties that Fabric needs to access in
different parts of the codebase. Those properties are, in fact,
available through refs as well, which breaks encapsulation.
This PR splits that into 2 separate fields, leaving the definition of
instance as:
- `node`: reference to the native node in the shadow tree.
- `publicInstance`: public instance provided to users via refs.
- Rest of internal fields needed by Fabric at the instance level.
This also migrates all the current usages of `canonical` to use the
right property depending on the use case.
To improve encapsulation (and in preparation for the implementation of
this [proposal to bring some DOM APIs to public instances in React
Native](https://github.com/react-native-community/discussions-and-proposals/pull/607)),
this also **moves the creation of and the access to the public instance
to separate modules** (`ReactFabricPublicInstance` and
`ReactFabricPublicInstanceUtils`). In a following diff, that module will
be moved into the `react-native` repository and we'll access it through
`ReactNativePrivateInterface`.
## How did you test this change?
Existing unit tests.
Manually synced the PR in Meta infra and tested in Catalyst + the
integration with DevTools. Everything is working normally.
Adding `.internal` to a test file prevents it from being tested in build
mode. The best practice is to instead gate the test based on whether the
feature is enabled.
Ideally we'd use the `@gate` pragma in these tests, but the `itRenders`
test helpers don't support that.
The www builds include disableLegacyContext as a dynamic flag, so we
should be running the tests in that mode, too. Previously we were
overriding the flag during the test run. This strategy usually doesn't
work because the flags get compiled out in the final build, but we
happen to not test www in build mode, only source.
To get of this hacky override, I added a test gate to every test that
uses legacy context. When we eventually remove legacy context from the
codebase, this should make it slightly easier to find which tests are
affected. And removes one more hack from our hack-ridden test config.
Given that sometimes www has features enabled that aren't on in other
builds, we might want to consider testing its build artifacts in CI,
rather than just source. That would have forced this cleanup to happen
sooner. Currently we only test the public builds in CI.
If something throws as a result of `flushSync`, and there's remaining
work left in the queue, React should keep working until all the work is
complete.
If multiple errors are thrown, React will combine them into an
AggregateError object and throw that. In environments where
AggregateError is not available, React will rethrow in an async task.
(All the evergreen runtimes support AggregateError.)
The scenario where this happens is relatively rare, because `flushSync`
will only throw if there's no error boundary to capture the error.
This adds `encodeReply` to the Flight Client and `decodeReply` to the
Flight Server.
Basically, it's a reverse Flight. It serializes values passed from the
client to the server. I call this a "Reply". The tradeoffs and
implementation details are a bit different so it requires its own
implementation but is basically a clone of the Flight Server/Client but
in reverse. Either through callServer or ServerContext.
The goal of this project is to provide the equivalent serialization as
passing props through RSC to client. Except React Elements and
Components and such. So that you can pass a value to the client and back
and it should have the same serialization constraints so when we add
features in one direction we should mostly add it in the other.
Browser support for streaming request bodies are currently very limited
in that only Chrome supports it. So this doesn't produce a
ReadableStream. Instead `encodeReply` produces either a JSON string or
FormData. It uses a JSON string if it's a simple enough payload. For
advanced features it uses FormData. This will also let the browser
stream things like File objects (even though they're not yet supported
since it follows the same rules as the other Flight).
On the server side, you can either consume this by blocking on
generating a FormData object or you can stream in the
`multipart/form-data`. Even if the client isn't streaming data, the
network does. On Node.js busboy seems to be the canonical library for
this, so I exposed a `decodeReplyFromBusboy` in the Node build. However,
if there's ever a web-standard way to stream form data, or if a library
wins in that space we can support it. We can also just build a multipart
parser that takes a ReadableStream built-in.
On the server, server references passed as arguments are loaded from
Node or Webpack just like the client or SSR does. This means that you
can create higher order functions on the client or server. This can be
tokenized when done from a server components but this is a security
implication as it might be tempting to think that these are not fungible
but you can swap one function for another on the client. So you have to
basically treat an incoming argument as insecure, even if it's a
function.
I'm not too happy with the naming parity:
Encode `server.renderToReadableStream` Decode: `client.createFromFetch`
Decode `client.encodeReply` Decode: `server.decodeReply`
This is mainly an implementation details of frameworks but it's annoying
nonetheless. This comes from that `renderToReadableStream` does do some
"rendering" by unwrapping server components etc. The `create` part comes
from the parity with Fizz/Fiber where you `render` on the server and
`create` a root on the client.
Open to bike-shedding this some more.
---------
Co-authored-by: Josh Story <josh.c.story@gmail.com>
To wait for the microtask queue to empty, our internal test helpers
schedule an arbitrary task using `setImmediate`. It doesn't matter what
kind of task it is, only that it's a separate task from the current one,
because by the time it fires, the microtasks for the current event will
have already been processed.
The issue with `setImmediate` is that Jest mocks it. Which can lead to
weird behavior.
I've changed it to instead use a message event, via the MessageChannel
implementation exposed by the `node:worker_threads` module.
We should consider doing this in the public implementation of `act`,
too.
This PR is now based on #26256
The original matching function for `hydrateHoistable` some challenging
time complexity since we built up the list of matchable nodes for each
link of that type and then had to check to exclusion. This new
implementation aims to improve the complexity
For hoisted title tags we match the first title if it is valid (not in
SVG context and does not have `itemprop`, the two ways you opt out of
hoisting when rendering titles). This path is much faster than others
and we use it because valid Documents only have 1 title anyway and if we
did have a mismatch the rendered title still ends up as the
Document.title so there is no functional degradation for misses.
For hoisted link and meta tags we track all potentially hydratable
Elements of this type in a cache per Document. The cache is refreshed
once each commit if and only if there is a title or meta hoistable
hydrating. The caches are partitioned by a natural key for each type
(href for link and content for meta). Then secondary attributes are
checked to see if the potential match is matchable.
For link we check `rel`, `title`, and `crossorigin`. These should
provide enough entropy that we never have collisions except is contrived
cases and even then it should not affect functionality of the page. This
should also be tolerant of links being injected in arbitrary places in
the Document by 3rd party scripts and browser extensions
For meta we check `name`, `property`, `http-equiv`, and `charset`. These
should provide enough entropy that we don't have meaningful collisions.
It is concievable with og tags that there may be true duplciates `<meta
property="og:image:size:height" content="100" />` but even if we did
bind to the wrong instance meta tags are typically only read from SSR by
bots and rarely inserted by 3rd parties so an adverse functional outcome
is not expected.
Currently, any commit to React causes an internal sync since the Git
commit hash is part of the build. This creates a lot more sync commits
and noise than necessary, see:
https://github.com/facebook/react/commits/builds/facebook-www
This PR changes the version string to be a hash of the target build
files instead. This way we get a new version with any change that
actually impacts the generated files and still have a matching version
across the files.
Some build artifacts contain multiple version strings. It seems like an
oversight to me that this `.replace` call just replaces the one that
happens to be first.
(This only affects our own internal repo; it's not a public API.)
I think most of us agree this is a less confusing name. It's possible
someone will confuse it with `console.log`. If that becomes a problem we
can warn in dev or something.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
Over the years, we've gradually aligned on a set of best practices for
for testing concurrent React features in this repo. The default in most
cases is to use `act`, the same as you would do when testing a real
React app. However, because we're testing React itself, as opposed to an
app that uses React, our internal tests sometimes need to make
assertions on intermediate states that `act` intentionally disallows.
For those cases, we built a custom set of Jest assertion matchers that
provide greater control over the concurrent work queue. It works by
mocking the Scheduler package. (When we eventually migrate to using
native postTask, it would probably work by stubbing that instead.)
A problem with these helpers that we recently discovered is, because
they are synchronous function calls, they aren't sufficient if the work
you need to flush is scheduled in a microtask — we don't control the
microtask queue, and can't mock it.
`act` addresses this problem by encouraging you to await the result of
the `act` call. (It's not currently required to await, but in future
versions of React it likely will be.) It will then continue flushing
work until both the microtask queue and the Scheduler queue is
exhausted.
We can follow a similar strategy for our custom test helpers, by
replacing the current set of synchronous helpers with a corresponding
set of async ones:
- `expect(Scheduler).toFlushAndYield(log)` -> `await waitForAll(log)`
- `expect(Scheduler).toFlushAndYieldThrough(log)` -> `await
waitFor(log)`
- `expect(Scheduler).toFlushUntilNextPaint(log)` -> `await
waitForPaint(log)`
These APIs are inspired by the existing best practice for writing e2e
React tests. Rather than mock all task queues, in an e2e test you set up
a timer loop and wait for the UI to match an expecte condition. Although
we are mocking _some_ of the task queues in our tests, the general
principle still holds: it makes it less likely that our tests will
diverge from real world behavior in an actual browser.
In this commit, I've implemented the new testing helpers and converted
one of the Suspense tests to use them. In subsequent steps, I'll codemod
the rest of our test suite.
## Summary
I'm going to start implementing parts of this proposal
https://github.com/react-native-community/discussions-and-proposals/pull/607
As part of that implementation I'm going to refactor a few parts of the
interface between React and React Native. One of the main problems we
have right now is that we have private parts used by React and React
Native in the public instance exported by refs. I want to properly
separate that.
I saw that a few methods to attach event handlers imperatively on refs
were also exposing some things in the public instance (the
`_eventListeners`). I checked and these methods are unused, so we can
just clean them up instead of having to refactor them too. Adding
support for imperative event listeners is in the roadmap after this
proposal, and its implementation might differ after this refactor.
This is essentially a manual revert of #23386.
I'll submit more PRs after this for the rest of the refactor.
## How did you test this change?
Existing jest tests. Will test a React sync internally at Meta.
When resuming a suspended render, there may be more Hooks to be called
that weren't seen the previous time through. Make sure to switch to the
mount dispatcher when calling use() if the next Hook call should be
treated as a mount.
Fixes#25964.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
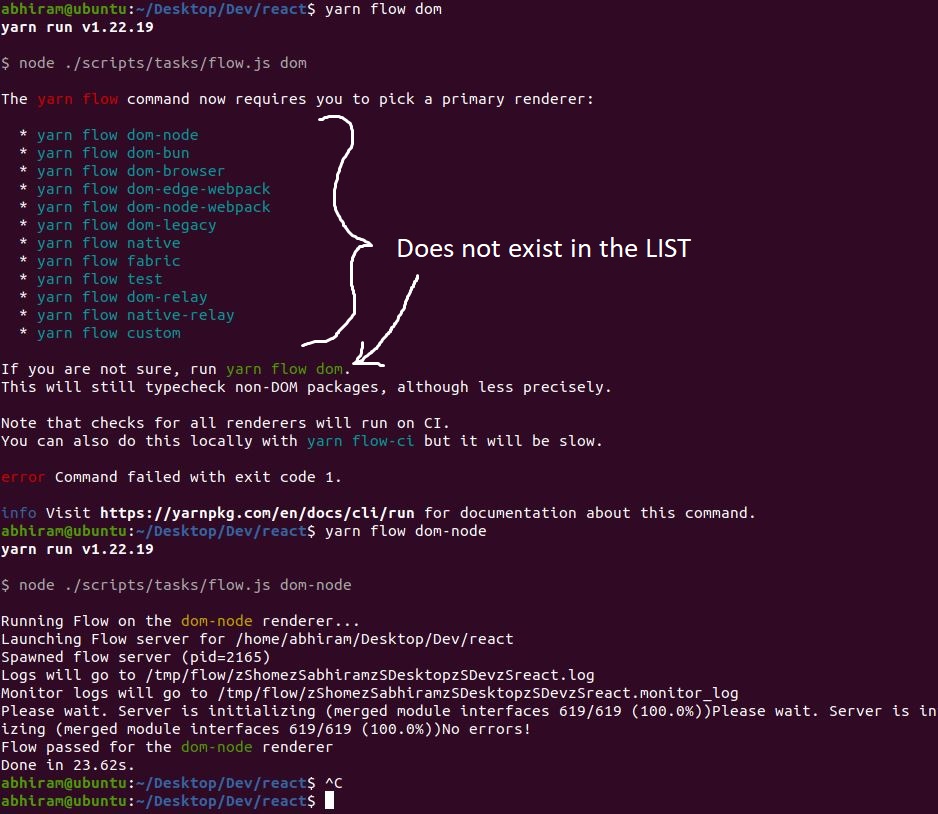
## Summary
The `yarn flow` command, as suggested for every PR Submission (Task No.
9), tells us `The yarn flow command now requires you to pick a primary
renderer` and provides a list for the same. However, in at the bottom of
the prompt, it suggests `If you are not sure, run yarn flow dom`. This
command `yarn flow dom` does not exist in the list and thus the command
does nothing and exits with `status code 1` without any flow test.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
While trying to submit a different PR for code cleaning, just during
submission I read the PR Guidelines, and while doing `yarn test`, `yarn
lint`, and `yarn flow`, I came across this issue and thought of
submitting a PR for the same.
## How did you test this change?
Since this code change does not change any logic, just the text
information, I only ran `yarn linc` and `yarn test` for the same.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Here is how the issue currently looks like:
Signed-off-by: abhiram11 <abhiramsatpute@gmail.com>
Co-authored-by: abhiram11 <abhiramsatpute@gmail.com>
This splits out the Edge and Node implementations of Flight Client into
their own implementations. The Node implementation now takes a Node
Stream as input.
I removed the bundler config from the Browser variant because you're
never supposed to use that in the browser since it's only for SSR.
Similarly, it's required on the server. This also enables generating a
SSR manifest from the Webpack plugin. This is necessary for SSR so that
you can reverse look up what a client module is called on the server.
I also removed the option to pass a callServer from the server. We might
want to add it back in the future but basically, we don't recommend
calling Server Functions from render for initial render because if that
happened client-side it would be a client-side waterfall. If it's never
called in initial render, then it also shouldn't ever happen during SSR.
This might be considered too restrictive.
~This also compiles the unbundled packages as ESM. This isn't strictly
necessary because we only need access to dynamic import to load the
modules but we don't have any other build options that leave
`import(...)` intact, and seems appropriate that this would also be an
ESM module.~ Went with `import(...)` in CJS instead.
## Summary
In rollup v1.19.4, The "treeshake.pureExternalModules" option is
deprecated. The "treeshake.moduleSideEffects" option should be used
instead, see
https://github.com/rollup/rollup/blob/v1.19.4/src/Graph.ts#L130.
## How did you test this change?
ci green
It's confusing to new contributors, and me, that you're supposed to use
`yarn build-combined` for almost everything but not fixtures.
We should use only one build command for everything.
Updated fixtures to use the folder convention of build-combined.
We currently have an awkward set up because the server can be used in
two ways. Either you can have the server code prebundled using Webpack
(what Next.js does in practice) or you can use an unbundled Node.js
server (what the reference implementation does).
The `/client` part of RSC is actually also available on the server when
it's used as a consumer for SSR. This should also be specialized
depending on if that server is Node or Edge and if it's bundled or
unbundled.
Currently we still assume Edge will always be bundled since we don't
have an interceptor for modules there.
I don't think we'll want to support this many combinations of setups for
every bundler but this might be ok for the reference implementation.
This PR doesn't actually change anything yet. It just updates the
plumbing and the entry points that are built and exposed. In follow ups
I'll fork the implementation and add more features.
---------
Co-authored-by: dan <dan.abramov@me.com>
## Summary
I ran into some two factor certification issue and had to resume the
publish script. However, this time if I confirmed the published package,
it will still try to publish the same version and fail. This is not
expected, and it blocks me from publishing the rest of the packages.
## How did you test this change?
I re-run the publish script after the change and successfully publish
the rest of the packages.
```
? Have you run the build-and-test script? Yes
✓ Checking NPM permissions for ryancat. 881 ms
? Please provide an NPM two-factor auth token: 278924
react-devtools version 4.27.2 has already been published.
? Is this expected (will skip react-devtools@4.27.2)? Yes
react-devtools-core version 4.27.2 has already been published.
? Is this expected (will skip react-devtools-core@4.27.2)? Yes
✓ Publishing package react-devtools-inline 23.1 secs
You are now ready to publish the extension to Chrome, Edge, and Firefox:
https://fburl.com/publish-react-devtools-extensions
When publishing to Firefox, remember the following:
Build id: 625690
Git archive: ******
```
## Hoistables
In the original implementation of Float, all hoisted elements were
treated like Resources. They had deduplication semantics and hydrated
based on a key. This made certain kinds of hoists very challenging such
as sequences of meta tags for `og:image:...` metadata. The reason is
each tag along is not dedupable based on only it's intrinsic properties.
two identical tags may need to be included and hoisted together with
preceding meta tags that describe a semantic object with a linear set of
html nodes.
It was clear that the concept of Browser Resources (stylesheets /
scripts / preloads) did not extend universally to all hositable tags
(title, meta, other links, etc...)
Additionally while Resources benefit from deduping they suffer an
inability to update because while we may have multiple rendered elements
that refer to a single Resource it isn't unambiguous which element owns
the props on the underlying resource. We could try merging props, but
that is still really hard to reason about for authors. Instead we
restrict Resource semantics to freezing the props at the time the
Resource is first constructed and warn if you attempt to render the same
Resource with different props via another rendered element or by
updating an existing element for that Resource.
This lack of updating restriction is however way more extreme than
necessary for instances that get hoisted but otherwise do not dedupe;
where there is a well defined DOM instance for each rendered element. We
should be able to update props on these instances.
Hoistable is a generalization of what Float tries to model for hoisting.
Instead of assuming every hoistable element is a Resource we now have
two distinct categories, hoistable elements and hoistable resources. As
one might guess the former has semantics that match regular Host
Components except the placement of the node is usually in the <head>.
The latter continues to behave how the original implementation of
HostResource behaved with the first iteration of Float
### Hoistable Element
On the server hoistable elements render just like regular tags except
the output is stored in special queues that can be emitted in the stream
earlier than they otherwise would be if rendered in place. This also
allow for instance the ability to render a hoistable before even
rendering the <html> tag because the queues for hoistable elements won't
flush until after we have flushed the preamble (`<DOCTYPE
html><html><head>`).
On the client, hoistable elements largely operate like HostComponents.
The most notable difference is in the hydration strategy. If we are
hydrating and encounter a hoistable element we will look for all tags in
the document that could potentially be a match and we check whether the
attributes match the props for this particular instance. We also do this
in the commit phase rather than the render phase. The reason hydration
can be done for HostComponents in render is the instance will be removed
from the document if hydration fails so mutating it in render is safe.
For hoistables the nodes are not in a hydration boundary (Root or
SuspenseBoundary at time of writing) and thus if hydration fails and we
may have an instance marked as bound to some Fiber when that Fiber never
commits. Moving the hydration matching to commit ensures we will always
succeed in pairing the hoisted DOM instance with a Fiber that has
committed.
### Hoistable Resource
On the server and client the semantics of Resources are largely the same
they just don't apply to title, meta, and most link tags anymore.
Resources hoist and dedupe via an `href` key and are ref counted. In a
future update we will add a garbage collector so we can clean up
Resources that no longer have any references
## `<style>` support
In earlier implementations there was no support for <style> tags. This
PR adds support for treating `<style href="..."
precedence="...">...</style>` as a Resource analagous to `<link
rel="stylesheet" href="..." precedence="..." />`
It may seem odd at first to require an href to get Resource semantics
for a style tag. The rationale is that these are for inlining of actual
external stylesheets as an optimization and for URI like scoping of
inline styles for css-in-js libraries. The href indicates that the key
space for `<style>` and `<link rel="stylesheet" />` Resources is shared.
and the precedence is there to allow for interleaving of both kinds of
Style resources. This is an advanced feature that we do not expect most
app developers to use directly but will be quite handy for various
styling libraries and for folks who want to inline as much as possible
once Fizz supports this feature.
## refactor notes
* HostResource Fiber type is renamed HostHoistable to reflect the
generalization of the concept
* The Resource object representation is modified to reduce hidden class
checks and to use less memory overall
* The thing that distinguishes a resource from an element is whether the
Fiber has a memoizedState. If it does, it will use resource semantics,
otherwise element semantics
* The time complexity of matching hositable elements for hydration
should be improved
This is the first of a series of PRs, that let you pass functions, by
reference, to the client and back. E.g. through Server Context. It's
like client references but they're opaque on the client and resolved on
the server.
To do this, for security, you must opt-in to exposing these functions to
the client using the `"use server"` directive. The `"use client"`
directive lets you enter the client from the server. The `"use server"`
directive lets you enter the server from the client.
This works by tagging those functions as Server References. We could
potentially expand this to other non-serializable or stateful objects
too like classes.
This only implements server->server CJS imports and server->server ESM
imports. We really should add a loader to the webpack plug-in for
client->server imports too. I'll leave closures as an exercise for
integrators.
You can't "call" a client reference on the server, however, you can
"call" a server reference on the client. This invokes a callback on the
Flight client options called `callServer`. This lets a router implement
calling back to the server. Effectively creating an RPC. This is using
JSON for serializing those arguments but more utils coming from
client->server serialization.
We're fixing the timing of layout and passive effects in React Native,
and adding support for some Web APIs so common use cases for those
effects can be implemented with the same code on React and React Native.
Let's take this example:
```javascript
function MyComponent(props) {
const viewRef = useRef();
useLayoutEffect(() => {
const rect = viewRef.current?.getBoundingClientRect();
console.log('My view is located at', rect?.toJSON());
}, []);
return <View ref={viewRef}>{props.children}</View>;
}
```
This could would work as expected on Web (ignoring the use of `View` and
assuming something like `div`) but not on React Native because:
1. Layout is done asynchronously in a background thread in parallel with
the execution of layout and passive effects. This is incorrect and it's
being fixed in React Native (see
afec07aca2).
2. We don't have an API to access layout information synchronously. The
existing `ref.current.measureInWindow` uses callbacks to pass the
result. That is asynchronous at the moment in Paper (the legacy renderer
in React Native), but it's actually synchronous in Fabric (the new React
Native renderer).
This fixes point 2) by adding a Web-compatible method to access layout
information (on Fabric only).
This has 2 dependencies in React Native:
1. Access to `getBoundingClientRect` in Fabric, which was added in
https://github.com/facebook/react-native/blob/main/ReactCommon/react/renderer/uimanager/UIManagerBinding.cpp#L644-
L676
2. Access to `DOMRect`, which was added in
673c7617bc
.
As next step, I'll modify the implementation of this and other methods
in Fabric to warn when they're accessed during render. We can't do this
on Web because we can't (shouldn't) modify built-in DOM APIs, but we can
do it in React Native because the refs objects are built by the
framework.
## Summary
- yarn.lock diff +-6249, **small pr**
- use jest-environment-jsdom by default
- uncaught error from jsdom is an error object instead of strings
- abortSignal.reason is read-only in jsdom and node,
https://developer.mozilla.org/en-US/docs/Web/API/AbortSignal/reason
## How did you test this change?
ci green
---------
Co-authored-by: Sebastian Silbermann <silbermann.sebastian@gmail.com>
We currently abuse the browser builds for Web streams derived
environments. We already have a special build for Bun but we should also
have one for [other "edge"
runtimes](https://runtime-keys.proposal.wintercg.org/) so that we can
maximally take advantage of the APIs that exist on each platform.
In practice, we currently check for a global property called
`AsyncLocalStorage` in the server browser builds which we shouldn't
really do since browsers likely won't ever have it. Additionally, this
should probably move to an import which we can't add to actual browser
builds where that will be an invalid import. So it has to be a separate
build. That's not done yet in this PR but Vercel will follow
Cloudflare's lead here.
The `deno` key still points to the browser build since there's no
AsyncLocalStorage there but it could use this same or a custom build if
support is added.
This updates the Flight fixture to support the new ESM loaders in newer
versions of Node.js.
It also uses native fetch since react-fetch is gone now. (This part
requires Node 18 to run the fixture.)
I also updated everything to use the `"use client"` convention instead
of file name based convention.
The biggest hack here is that the Webpack plugin now just writes every
`.js` file in the manifest. This needs to be more scoped. In practice,
this new convention effectively requires you to traverse the server
graph first to find the actual used files. This is enough to at least
run our own fixture though.
I didn't update the "blocks" fixture.
More details in each commit message.
The "dom" configuration is actually the node specific configuration. It
just happened to be that this was the mainline variant before so it was
implied but with so many variants, this is less obvious now.
The "bun" configuration is specifically for "bun". There's no "native"
renderer for "bun" yet.
The old version of prettier we were using didn't support the Flow syntax
to access properties in a type using `SomeType['prop']`. This updates
`prettier` and `rollup-plugin-prettier` to the latest versions.
I added the prettier config `arrowParens: "avoid"` to reduce the diff
size as the default has changed in Prettier 2.0. The largest amount of
changes comes from function expressions now having a space. This doesn't
have an option to preserve the old behavior, so we have to update this.
This renames Module References to Client References, since they are in
the server->client direction.
I also changed the Proxies exposed from the `node-register` loader to
provide better error messages. Ideally, some of this should be
replicated in the ESM loader too but neither are the source of truth.
We'll replicate this in the static form in the Next.js loaders. cc
@huozhi @shuding
- All references are now functions so that when you call them on the
server, we can yield a better error message.
- References that are themselves already referring to an export name are
now proxies that error when you dot into them.
- `use(...)` can now be used on a client reference to unwrap it server
side and then pass a reference to the awaited value.
{kind=link}